这篇笔记整理了variant calling(SNP和InDel)的技术原理。
相关信息
参考资料:
- https://ming-lian.github.io/2019/02/08/call-snp/
术语
- Single Nucleotide Polymorphism (SNP):群体中特定位点上两种或多种不同的核苷酸(通常是转换Transition「同类碱基置换,如嘌呤之间AtoG或嘧啶之间CtoT」或颠换Transversion)存在,且在该群体中的等位基因频率通常高于 1%。该术语倾向于描述群体遗传学、物种进化或亲缘关系分析中的多态性,属于胚系变异。
- SNP calling:旨在通过高通量测序数据比对,识别个体基因组中与参考序列不同的单个碱基变异(SNP)。
- QTL:QTL的划定是一个基于统计学推断的过程,它没有全球统一的、绝对的物理范围或SNP数量标准,但有一套被广泛接受的科学方法和经验性阈值。详见[[02_QTL的判定]]
- expression quantitative trait loci (eQTLs):指基因组中能影响特定基因(mRNA或蛋白质)表达水平的遗传变异(通常为SNP)。它通过研究DNA变异与基因表达量的相关性,揭示遗传突变调控表达的机制,主要分为顺式(cis-eQTL,近距离,上下游1Mb)和反式(trans-eQTL,远距离不同染色体或相距>5Mb)两类。
- Genotype-Tissue Expression Project (GTEx数据库):是目前最全的人类组织特异性eQTL数据库。
- Genomics Reference Panel:一个包含了大量个体全基因组测序(WGS)数据的“高密度变异数据库”它记录了群体中极其丰富的自然遗传变异
分析原理
本项目的重测序分析流程由 ACGT101_ReSeq_4.6_gpu.pl 驱动,目标是从原始测序 reads 出发,构建高质量比对结果,进行变异检测(SNP / InDel / SV / CNV)与功能注释,为后续关联分析与功能解释提供可靠的基因型信息。下面按照实际流程顺序,说明每一步“在做什么”以及“为什么要做”。
参数读取与环境准备
- 做什么:
脚本首先通过-i parameter_ACGT101_ReSeq.txt读取项目参数,加载:- 集群运行配置(
partition / node / interval / maxProc / GPU / numGPUs / GATK_threads / GATK_mem / anno_mem等) - 目录结构(
INPUT / CLEANDATA / PROCESSDATA / OUTPUT / DONE) - 样本信息文件
SAMPLE_INFO(样本名与文库名对应关系) - 参考基因组与注释(
ref_db / ref_anno / SnpEff_version / chr_num等) - 是否只做质控(
only_QC)、是否群体联合分析(population)、变异检测模式(tool=U/H)、是否调用 SV / CNV(SV / CNV)等。
- 集群运行配置(
- 为什么:
统一在一个参数文件中配置所有关键信息,可以保证流程的可复现性和不同项目间的可移植性。脚本后续所有子步骤都只依赖该参数文件,不需要手动改脚本,从而减少人为出错风险。
样本信息读取与数据列表构建
- 做什么:
- 从
Sample_Info.txt中读取所有待分析样本及文库名,生成smp_list。 - 在
INPUT目录中搜索各样本的原始R1/R2fastq.gz,生成input_list.txt(样本名与双端文件路径列表)。 - 质控后再在
CLEANDATA中生成cleandata_list.txt,用于后续比对。
- 从
- 为什么:
通过标准化的数据列表显式描述“每个样本对应哪些 FASTQ 文件”,可以:- 让后续所有步骤都在同一份样本列表上工作,避免样本遗漏或顺序错乱;
- 支持批量、多样本自动化处理,而不需要为每个样本编写独立命令。
原始数据质控:fastp + FastQC
- 做什么:
1)fastp对input_list.txt中的每个样本进行质控:- 去接头、去除含过多 N 的 reads(由
n_base_limit控制); - 剪切两端低质量碱基,丢弃过短 reads(由
length_required控制); - 输出 Clean reads 到
CLEANDATA,并生成每个样本的质控报告(json/html)。
2)fastp_stat.py汇总所有样本的 fastp 结果,生成整体质控统计表OUTPUT/data_stat.txt。
3)对 Clean data 再运行 FastQC,补充基础质控图表。
- 去接头、去除含过多 N 的 reads(由
- 为什么:
- 去除低质量 reads 和接头污染可以降低假阳性变异的产生,为比对与变异检测提供干净输入;
- 统一的质控汇总报告方便评估不同样本之间的数据量、Q30 比例、接头污染等是否异常;
- 若
only_QC=T,流程在此停止,可以用于项目早期快速评估数据质量而不浪费后续计算资源。
参考基因组处理与索引构建
- 做什么:
1)ref_GC_len计算ref_db中每条序列的长度和 GC 含量,输出genome.fa.len。
2)根据注释和chr_num判断是否进入link模式:- 若染色体/序列条数 > 设定阈值(如 65),说明有大量 scaffold,流程会选择长度前
chr_num条作为“主染色体”,生成chr_id.txt。
3)prepare_ref在Ref目录中对参考基因组进行精简与重命名(若需要 link): - 生成新的
ref.genome.fa / ref.genome.gff、对应长度文件以及id_table.txt(记录原始坐标与新坐标的映射关系)。
4)对最终使用的参考序列构建 BWA / samtools / Picard 索引。
- 若染色体/序列条数 > 设定阈值(如 65),说明有大量 scaffold,流程会选择长度前
- 为什么:
- 计算 GC 和长度是后续 CNV 分析与绘图的基础;
- 对 scaffold 极多的基因组进行“主染色体抽取 + 重命名”可以显著降低比对与下游分析复杂度,加快运行并避免在大量微小 scaffold 上产生噪声;
- 坐标映射表
id_table.txt让后续可以在精简参考上完成计算,再把结果还原回原始参考坐标,兼顾效率与结果可解释性; - 构建各种索引是 BWA / samtools / GATK 等工具运行的前提。
比对:CPU 模式与 GPU(Parabricks)模式
- 做什么:
根据map_soft选择比对方案:- CPU 模式 (
map_soft=CPU):- 使用
bwa mem将 Clean reads 比对到参考基因组,生成 SAM; - 用
samtools view + sort转换并排序为 BAM; - 再用 Picard
MarkDuplicates标记/去除 PCR duplicates,得到*.rmdup.bam。
- 使用
- GPU 模式 (
map_soft=GPU):- 调用 Parabricks
pbrun fq2bam,在 GPU 上一次性完成比对 + 排序 + 去重复,直接产生*.rmdup.bam和重复率统计。
- 调用 Parabricks
- CPU 模式 (
- 为什么:
- 高质量的比对结果是 SNP / InDel / SV / CNV 检测的基础;
- 去除/标记 duplicates(见下文 duplicates 产生原因)可以减少 PCR 扩增和光学重复带来的假阳性信号;
- GPU 加速能在保证结果与标准 GATK 流程一致的前提下,大幅缩短运行时间,特别适合全基因组重测序和群体项目。
比对结果质量评估与深度/覆盖统计
- 做什么:
insertsize计算文库插入片段长度分布,输出插入片段图和统计表;samtools flagstat生成每个样本的比对统计(比对率、成对比对率、重复率等);samtools depth计算碱基层面的测序深度,depth_stat.pl汇总为:- 各染色体平均深度、不同深度阈值下的覆盖比例;
- 再绘制平均深度柱状图、深度分布曲线、覆盖度图等。
- 生成 BAM 索引(
.bai),并汇总所有样本的比对与覆盖信息到mapped_cover_stat.txt。
- 为什么:
- 插入片段异常(比如极短或极长)可能提示文库构建问题;
- 比对率和重复率是评估测序数据可用性的重要指标:比对率太低可能是污染或参考版本不匹配;
- 深度和覆盖度直接决定变异检测的灵敏度与可靠性,需要在变异调用前进行全局评估;
- BAM 索引是 GATK、samtools 等对局部区域进行高效随机访问的前提。
变异检测:SNP & InDel
根据 tool(UnifiedGenotyper 或 HaplotypeCaller)以及 population(单样本或群体)选择不同分支,但核心思想相同:在高质量比对基础上,对每个位点的碱基观察数据构建统计模型,评估是否存在真实变异以及每个样本的基因型。
UnifiedGenotyper 流程(tool=U,适合混池等场景)
- Realign(
realign)- 对 BAM 进行 GATK3 的局部重比对(IndelRealigner),修正 indel 区域附近的错配模式。
- 目的:减小 indel 周围误配导致的假阳性 SNP,提高 UG 在复杂区域的召回与精度。
- Call 变异(
gatk_pop/gatk_single)- 群体模式下,各样本联合进行 UG 调用,得到群体 VCF;
- 单样本模式下,逐样本调用。
- 目的:利用群体信息提高变异检测的统计功效,特别是在中低深度时减少漏检。
- SNP / InDel 拆分与过滤
SelectVariants将 VCF 按变异类型拆成 SNP 和 InDel;VariantFiltration依据硬过滤表达式(QD / QUAL / FS / SOR / MQ / MQRankSum / ReadPosRankSum等)给每条变异打标签,然后只保留PASS记录。- 目的:通过经验阈值过滤掉深度过低、质量过差、链偏好严重等可疑位点,得到一套高可信度候选变异集。
HaplotypeCaller 流程(tool=H,本项目默认推荐)
- GVCF 生成(
gatk_gvcf_gpu或 CPU 版 HC)- 对每个样本的
rmdup.bam运行 HaplotypeCaller,输出sample.g.vcf.gz。 - 与 UG 不同,HC 在局部区域进行重组装,构建 haplotype,从而更好地处理 indel 和复杂变异。
- 目的:以 gVCF 形式完整记录每个样本在全基因组的“基因型证据”,为群体联合 Genotype 做准备。
- 对每个样本的
- Genotype 合并(
genotype_vcf_pop/genotype_vcf_single)- 群体模式下,利用
easy_JVC.pl将所有样本 gVCF 按染色体和区间切分,分批CombineGVCFs + GenotypeGVCFs,最终合并成群体级 VCFpop.vcf; - 单样本模式下,对每个 gVCF 直接 Genotype。
- 目的:在保持样本间信息共享的同时,控制每个任务的计算负载,使大样本群体分析也能稳定完成。
- 群体模式下,利用
- SNP / InDel 拆分与过滤(GATK4)
- 与 UG 分支类似,通过
SelectVariants + VariantFiltration+awk保留PASS记录。 - 目的:得到一套标准化、质量可控的 SNP / InDel 候选位点,用作后续功能注释与关联分析的输入。
- 与 UG 分支类似,通过
link 模式下的坐标还原
- 做什么:
- 若在前面参考精简步骤中进入
link模式,所有变异检测和过滤都是在“重排后的参考”上完成的; filter_pos_convert和result_pos_convert使用id_table.txt将过滤后的 SNP / InDel VCF 坐标转换回原始参考坐标。
- 若在前面参考精简步骤中进入
- 为什么:
- 许多公共数据库(如 Ensembl/NCBI 注释、已有 QTL/eQTL 结果)都是基于原始参考构建的;
- 通过坐标还原,可以在保持计算高效的同时,保证最终结果与外部资源以及基因组浏览器完全对齐。
SnpEff 建库与变异功能注释
- 做什么:
- 先根据
ref_db / ref_anno / SnpEff_version构建或更新 SnpEff 数据库,生成snpEffectPredictor.bin; - 对过滤后的 SNP / InDel VCF 运行 SnpEff
ann,得到带有功能注释字段(ANN)的 VCF 以及对应的统计报表(csv/html); - 通过
extract_ANN.pl从 ANN 字段中提取易读的注释表(*.anno.txt),包括变异是否位于 exon/intron/UTR、是否导致同义/非同义、剪接位点破坏等。
- 先根据
- 为什么:
- 仅知道“这个位点发生了 A→G”还不够,需要知道它可能如何影响基因功能:
- 是否改变氨基酸?
- 是否位于启动子或剪接位点?
- 是否落在已知基因或转录本上?
- 这些功能注释是后续 pQTL / eQTL / GWAS 信号解释的关键证据之一。
- 仅知道“这个位点发生了 A→G”还不够,需要知道它可能如何影响基因功能:
变异统计与可视化
- 做什么:
snp_mut_stat计算 Ti/Tv 比值、杂合/纯合比例等整体质量指标;snp_stat / indel_stat基于*.anno.csv统计变异在不同基因区域和功能类别中的分布;snp_plot / indel_plot调用 R 脚本绘制功能分布饼图等可视化图。
- 为什么:
- Ti/Tv 比值和 Het/Hom 比例是评估变异结果整体可信度的常用指标(例如 Ti/Tv 过低往往提示大量假阳性);
- 功能类别统计有助于从宏观上理解本项目的变异谱特征,例如是否富集于非同义、剪接区、启动子等。
SV 与 CNV 检测
- SV(结构变异)
- 使用
lumpy等工具,基于异常配对 reads 和拆分 reads 检测大片段缺失、插入、倒位等结构变异,并做类型/大小统计。 - 目的:捕获大于单碱基或小 indel 的结构变化,这些变异往往对基因剂量或染色体结构有较大影响。
- 使用
- CNV(拷贝数变异)
- 将参考基因组拆分为按染色体的窗口,结合 GC 含量和测序深度,利用
call_CNV.pl估计每个样本的相对 copy number,输出 CNV 片段以及与基因注释交集的结果。 - 目的:发现基因或大片段的拷贝数增减,这类变异在适应性进化、疾病易感性和产量性状中往往扮演重要角色。
- 将参考基因组拆分为按染色体的窗口,结合 GC 含量和测序深度,利用
总结报告与交付物
- 做什么:
- 对单样本调用
summary_sig.pl,对群体项目调用summary.pl,收集质控、比对、深度覆盖、变异统计、功能注释等多项结果,整理到Summary目录下的标准交付结构中。
- 对单样本调用
- 为什么:
- 将复杂的多步流程抽象成易于阅读和交付的报告与表格,方便下游的统计分析、可视化和客户/合作方解读;
- 同时也为之后的 QTL / GWAS / pQTL / eQTL 分析提供了系统化的起点——即一套质量可控、注释完备的基因型矩阵与辅助统计信息。
后续关联分析 (Association)
-
基因型 (Genotype): 通过 SNP Calling 获得每个样本在特定位点的等位基因状态(如 0, 1, 2,代表突变个数)。
- 表型 (Phenotype): 这里的性状是分子的“量”,例如蛋白质丰度。
统计模型会对全基因组的 SNP 逐一进行检验。
-
原假设 (H0): 该 SNP 与蛋白质丰度无关(相关系数 β=0)。
-
备择假说 (H1): 该 SNP 的基因型剂量变化会导致蛋白质丰度发生显著变化。
详情见[[02_GWAS关联分析]]
后续功能分类与证据评估
-
Cis-pQTL: 显著 SNP 物理位置靠近编码基因。这提供了较强的先验概率,暗示其可能直接影响转录或翻译。
-
Trans-pQTL: 显著 SNP 远离编码基因。
-
诊断性评估: 此时需要评估是否存在连锁不平衡 (LD)。即:该 SNP 是真正的功能位点,还是仅仅与功能位点距离太近而被“带”出来的信号?
duplicates的产生原因
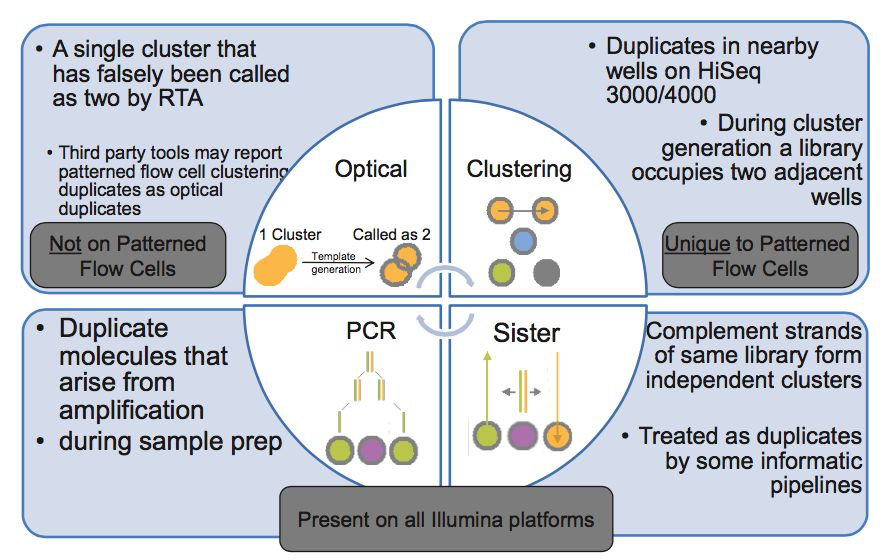
PCR duplicates(PCR重复)
PCR扩增时,同一个DNA片段会产生多个相同的拷贝,第4步测序的时候,这些来源于同一个拷贝的DNA片段会结合到Fellowcell的不同位置上,生成完全相同的测序cluster,然后被测序出来,这些相同的序列就是duplicate
Cluster duplicates
生成测序cluster的时候,某一个cluster中的DNA序列可能搭到旁边的另一个cluster的生成位点上,又再重新长成一个相同的cluster,这也是序列duplicate的另一个来源,这个现象在Illumina HiSeq4000之后的Flowcell中会有这类Cluster duplicates
Optical duplicates(光学重复)
某些cluster在测序的时候,捕获的荧光亮点由于光波的衍射,导致形状出现重影(如同近视散光一样),导致它可能会被当成两个荧光点来处理。这也会被读出为两条完全相同的reads
Sister duplicates
它是文库分子的两条互补链同时都与Flowcell上的引物结合分别形成了各自的cluster被测序,最后产生的这对reads是完全反向互补的。比对到参考基因组时,也分别在正负链的相同位置上,在有些分析中也会被认为是一种duplicates。