这篇笔记把GWAS实战里最常“落地”的部分集中整理:常见输入输出文件长什么样、Manhattan/QQ图怎么看、以及最终交付物通常包含哪些表。
一套GWAS项目常见输入/输出
输入(Inputs)
- 表型文件(phenotype)
- 最少:样本ID + 性状值
- 常见扩展:性别/年龄/批次/群体等协变量
- 基因型文件(genotype)
- WGS/芯片得到的变异矩阵或常见格式(如PLINK系、VCF系)
- 协变量文件(covariates,可选)
- PCA前几个PC、批次、测量因素等
- 亲缘关系/GRM(可选)
- 混合线性模型常用
输出(Outputs)
- 变异集(Variant calling / QC后位点集合)
- 过滤后的 SNP/INDEL(例如VCF/BED等载体)
- 关联结果表(Association summary)
- 每个位点常见字段:CHR、POS、SNP ID、A1/A2、AF/MAF、$\hat{\beta}$、SE、P
- 注释结果(Annotation)
- 位点到基因/区域的注释(如SnpEff/ANNOVAR等的输出)
- 报告与图(Report)
- 关键图表、lead SNP列表、候选区间、解释文字
Manhattan图怎么看
Manhattan图展示每个SNP的显著性(常用 \(-\log_{10}(P)\))随基因组位置的分布。
- 峰(peak):通常是一个LD块内的一簇SNP共同抬高;最高点通常称为lead SNP
- 峰宽:往往由LD范围决定,不等于“因果区间真实长度”
- 跨染色体对比:某些性状可能只在少数染色体出现强信号,也可能多峰(多基因性状常见)
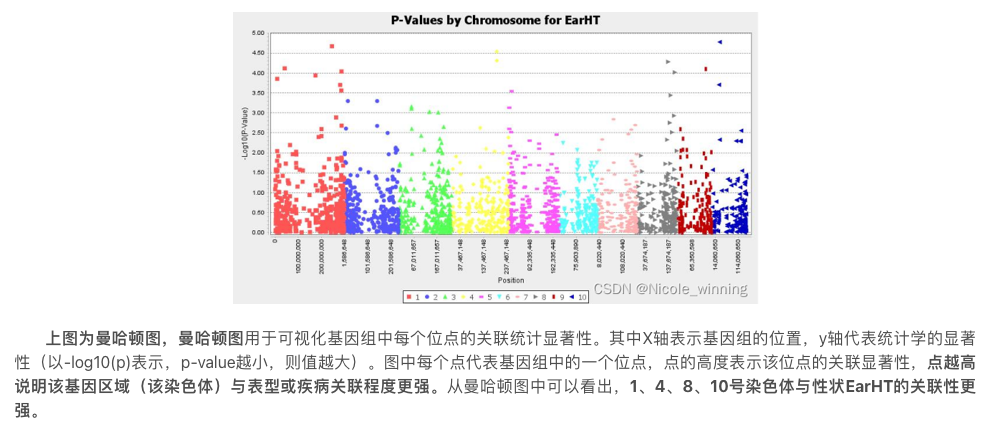
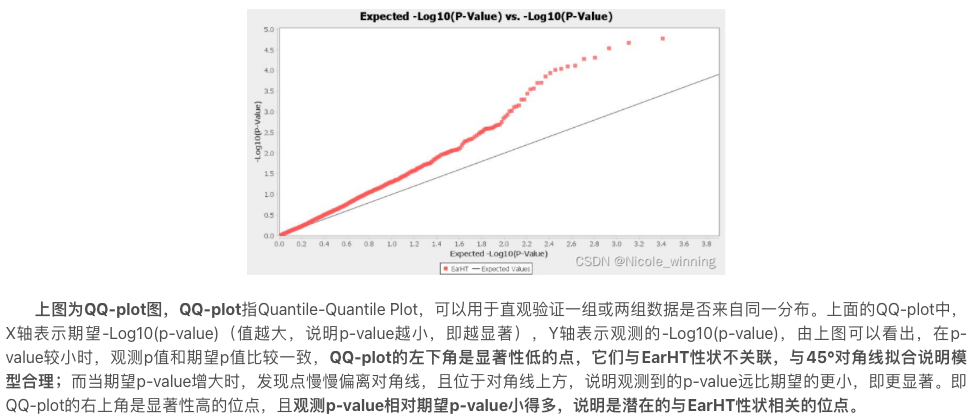
QQ-plot怎么看
QQ图把观测到的P值分布与零假设下的期望分布对比,用来快速判断是否存在系统性通胀/偏倚。
- 对角线附近:整体校正较合理
- 整体上翘(早期偏离):可能有群体结构/批次效应/模型不合适导致的通胀
- 仅尾部上翘:常见于确有真实关联信号(强信号导致尾部偏离)
GWAS后续分析常见“交付物清单”(可作为Checklist)
- 功能注释(annotation)
- 变异类型/区域:外显子、内含子、启动子、基因间区
- 编码区:同义/非同义、潜在功能影响
- 候选基因筛选与富集
- 区间锁定:按LD衰减距离或固定窗口(如±100 kb)收集候选基因
- GO/KEGG等富集,辅助解释
- 单倍型/LD块与精细定位
- LD block结构、条件分析
- 细化到候选变异集合(credible set)
- 最终报告(report)
- lead SNP列表(含效应方向、频率、P、注释)
- 关键图(Manhattan、QQ、局部区域图、LD热图等)
- 解释文本:可能机制、与既往研究一致性、局限性